対応分析(コレスポンデンス分析)のラベルのはみだしをWordで調整する
はじめに
Rで対応分析などを行ってplotすると、ラベルの端が切れてしまうことがあります。そのときの対処法のメモ。
現象
次のような現象が今回の処理の対象です。

対応方法
Rのコマンド例:
library(MASS)
plot(corresp(jikken,nf=5))
(1)plot後、右クリックをして「メタファイルにコピー」
※ビットマップではだめです。
(2)Wordの貼り付け
(3)図を右クリックして、「図の編集」

そうすると、後ろに隠れていた部分が見えるようになります(原理は不明ですが、おそらく編集するためにすべてを可視化するのかもしれません)。

※図が「前面」に変更されてしまいますので、図を選択して「文字列の折り返し」から「四角」や「行内」など望むものを選んでください。
Gmailで添付ファイルのダウンロードが失敗する場合の対処法
はじめに
gmailで添付ファイルが送られてきてChrome等のブラウザからダウンロードしようとすると、「失敗―ダウンロード エラー」となることがあります。

ブラウザを変えても、キャッシュを削除してもうまくいかない場合の対処法を書いておきます。
解決策:ファイル名を変更する
解決策は、「ファイル名を変更する」ということです。アルファベットなどの単純なファイル名にしてダウンロードすれば、エラーは回避されます。
原因は?
この原因はOS間の「ユニコードの正規化の違い」のようです。
「ダ」「ポ」「グ」などの文字列は、一文字(ダ)として表現される場合と結合文字(タ+濁点)として表現される場合があります。このずれによりファイル名を認識できないというのが原因と考えられます。
参考:Unicodeの特殊な文字 “結合文字列” | ものかの
例えばMacで「ダウンロード.pdf」というファイルを作り、Windowsでダウンロードしようとするとおそらく失敗します(再現していませんが)。
まとめ
- 添付ファイルのダウンロードを失敗した場合、「ファイル名」を変えてみる(アルファベットのみ推奨)
- OS間の違いを考えると、ファイルはアルファベットで命名するのが無難
Rの対応分析でラベルの重なりを解消する
はじめに
Rで対応分析を行う場合、変数が多いとラベルが重複してしまう可能性があります。その場合、plot関数だけではうまく処理できません。
地道なやり方としてはメタファイルに出力して、Adobe Illustratorなどで処理することも可能ですが、ここではwordcloudライブラリを使った方法をメモしておきます(参考:wordcloud makes words less cloudy « Fells Stats)。
用意するもの
- R(できるだけ最新版を)
- MASSライブラリをインストール
- wordcloudライブラリをインストール
- 分析するデータ
→ここでは次のデータ(部分抜粋。単語は38行あります。A~Eはジャンルだと考えてください)を処理します。

plotしてみる
MASSライブラリを読み込み、corresp関数で対応分析を実行しplotします。
>library(MASS)
>words=read.table("clipboard",header=T)
> words.corresp=corresp(words,nf=4)
> plot(words.corresp)
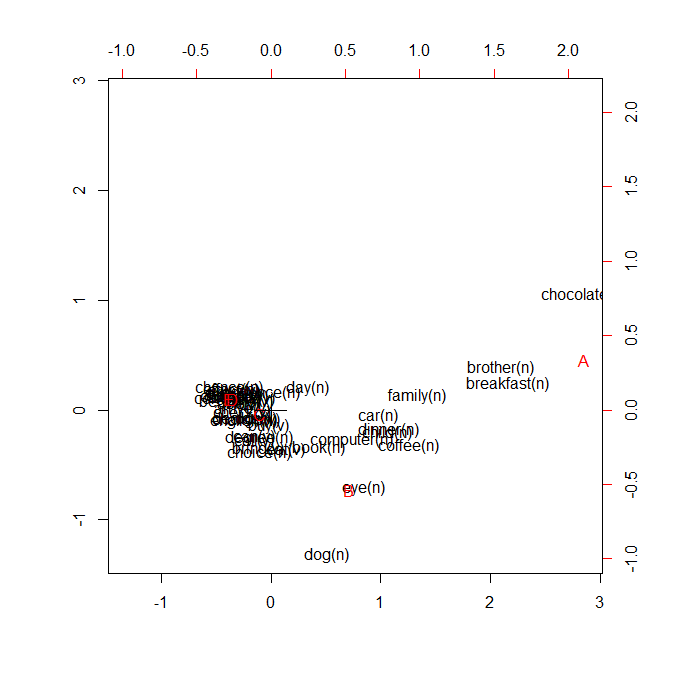
これだとかなり重なりがあり、可読性が低い状態です。
予備知識
オブジェクト型はclass関数で見ることができます。
> class(words.corresp)
[1] "correspondence"
correspondence型は$cscoreで列側(上のデータではA、B、C、D、E)のスコアに、$rscoreで行側(単語)にアクセスできます。
例えば:
> words.corresp$cscore
[,1] [,2] [,3] [,4]
A 3.6911623 1.6803089 0.1717679 0.03243607
B 0.9217827 -2.6917578 0.7224602 -0.10977487
C -0.1368556 -0.1294318 -1.6574275 0.22612367
D -0.4579921 0.3830560 0.4693191 -1.04030145
E -0.4899167 0.3618963 0.8463817 1.69203612
となります。
また、$corで相関係数を表示します。
> words.corresp$cor
[1] 0.57024044 0.20068781 0.14170275 0.08328265
$cor[1]が第1主成分の相関係数、$cor[2]が第2主成分の相関係数です。
Rのplot関数は、2つの系列のスコア($cscoreと$rscore)を同時に配置するために、それぞれの固有値を相関係数で重み付けをしています。
例えば、Aの第1主成分3.69は(X軸)、第1主成分の相関係数0.57を乗じてプロットされます。
このとき、plot関数で作成される座標軸のスケールにも注意が必要です。図中、上と右に記されるのがrscoreの系統、下と左にあるのがcscoreの系統です。原点だけ一致しています(この見え方はwordcloudを使うと軸を固定することになるので少し変わります)。
wordcloudを使う
ではwordcloudを使って描写してみましょう。この関数はそもそもワードクラウドを作成するためものです。
しかしながら、texplot関数という大変良くできたものを含んでおり、これを使うことでラベルの重なりを解消することができます。
考え方としては、rscoreとcscoreをtextplot関数で同一画面に上書きで作画する、ということです。このとき、座標軸を固定するのがポイントです。そのためにはxlimとylim(軸の最小値と最大値)を同じにする必要があります。
動的にも取得できますが、先ほどのbiplotをみて決めるのが楽だと思います。今回はxlim=c(-1.5,3),ylim=c(-1.5,2)で固定します。
textplot関数は第1引数にXの値を、第2引数にYの値を、第3引数にラベルを取ります。
まず、ライブラリを読み込みます。
>library(wordcloud)
行と列、それぞれのスコアを変数に格納します。
> words.corresp.rscore=words.corresp$rscore
> words.corresp.cscore=words.corresp$cscore
rscore(単語の方)からプロットしてみましょう。
>textplot(words.corresp.rscore[,1]*words.corresp$cor[1],
words.corresp.rscore[,2]*words.corresp$cor[2],rownames(words.corresp.rscore),
xlim=c(-1.5,3),ylim=c(-1.5,2))
ここで*words.corresp$cor[1]を乗じているのは、重み付けのためです。つまり、words.corresp.rscore[,1]*words.corresp$cor[1]は第1主成分の列に相関係数を乗じて座標点を計算する、という意味になります。第2主成分も同様です。
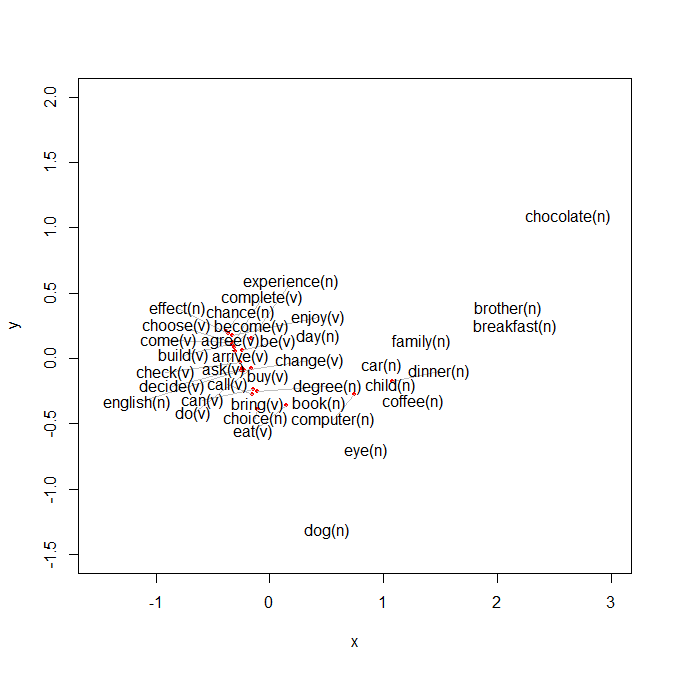
だいぶきれいに描画できました。
では、ここにcscoreのほうも重ねてみましょう。グラフを上書きするにはpar(new=T)を指定しいます。
> par(new=T)
次いでtextplotを行います。xlimとylimを同じにすることを忘れずに。
>textplot(words.corresp.cscore[,1]*words.corresp$cor[1],
words.corresp.cscore[,2]*words.corresp$cor[2],rownames(words.corresp.cscore),
xlim=c(-1.5,3),ylim=c(-1.5,2), col="blue", font=2)
色は青(col="blue")、そして太字(font=2)にしています。
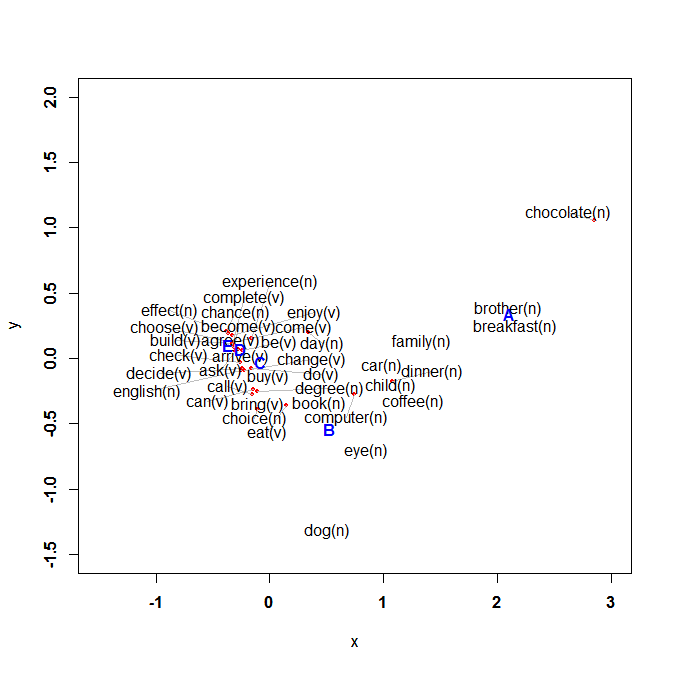
まとめ
対応分析をplotするとラベルが重なることがある
wordcloudライブラリのtextplotを使うと自動的に重なりを調整してくれる
引数を渡すには$cscore, $rscore, rownames関数を使って値を取得する。その際、$corで重み付けをする
RMeCabを使ってwordcloudを作る
(1)RMeCabをインストール
install.packages("RMeCab", repos = "http://rmecab.jp/R")
※場合によっては管理者権限でRを起動する必要あり(ショートカットを右クリックから)
(2)"tm"と"wordcloud"をpackagesのメニューからインストール
(3)パッケージの読み込み
library(wordcloud)
library(RMeCab)
(3)分析対象を決める
分析対象のテキストをマイドキュメント(Rが自動で参照できるフォルダ)に設置。
ここではdata.txtとした。
(4)RMeCabで頻度を解析
data.freq=RMeCabFreq("data.txt")
→結果はこのようになる。
Term Info1 Info2 Freq
1 え フィラー * 1
2 ありがとう 感動詞 * 1
3 おお 感動詞 * 1
4 はい 感動詞 * 1
5 C 記号 アルファベット 1
6 ・ 記号 一般 29
(5)データのフィルタリング
data.sub=subset(data.freq, Info1=="名詞" | Info1=="動詞", c(Term,Freq))
# 名詞か動詞を指定。条件には「|」(or)か「&」を使う(||、&&は不可)
#subsetはデータフレームから条件を指定してデータを抜き出せる関数。
#subset(データ,条件(列名で指定可能),出力列)
data.sub2=subset(data.freq, Info1=="名詞" & Info2!="数", c(Term, Freq))
#名詞を指定、数を除外
(6)描画
wordcloud(data.sub[,1], freq=data.sub[,2], min.freq=3,random.order=F)
#一つ目で単語の行、freq=で単語の頻度、min.freqで最低頻度、random.orderで配置を決める
★色をつける
wordcloud(data.sub[,1],freq=data.sub[,2],min.freq=3,random.order=F, color=c("pink","yellow","green", "blue", "red"))
#右が頻度大の色
wordcloud(data.sub[,1],freq=data.sub[,2],min.freq=3,random.order=F, color=rainbow(7))
#rainbowで色数を指定
★データの書き出し
write.table (data, file = "data.txt", sep = "\t", quote = FALSE, row.names = FALSE)
Wimaxで追加機器オプションでルーターを登録する
Wimaxでは、月々の基本料金+200円で、ルーターを追加登録できます。
これを行うことで、「家用」「外出用」などを使い分けることができ、便利です(※ただし、2つのルーターから同時接続は不可。同時接続を行うプラン(WiMAXファミ得パック)もありますが、これは+2400円程度かかります)。
その追加機器の登録方法ですが、躓いたのでメモ。
ルーター1(回線契約をしているもの)
こちらに接続をする必要はありません。
ルーター2(追加する方)
こちらにPCからアクセスします。ルーターにSSIDとパスワードが記載されているはずですので、PCの無線スポットの一覧から選択し、このルーターに接続します(普通にインターネットにつなぐ要領)。
すると設定画面が開きます。開かない場合は、ブラウザを起動します。
その画面から、プロバイダを選び、手持ちのIDとパスワード(SSIDではなく、プロバイダの会員ページに入るものです)でログインします。
追加機器に関するメニューがありますので、そこから登録します。